Introduction
Mica is an advanced web application designed to create data web portals for large-scale epidemiological studies or multiple-study consortia. It provides a structured description of consortia, studies, annotated and searchable data dictionaries, and data access request management.
Mica is built upon a multi-tier architecture consisting of several RESTful server and client applications. The table below list each application with a brief description:
Application |
Description |
|---|---|
Mica Server |
Java server providing web services (REST) for managing, storing, searching Mica Domain content and communicating with other servers listed below. |
Optional Java server providing web services (REST) for importing, transforming and analyzing study variables. |
|
Java server providing web services (REST) for user management and notifications. |
|
Mica Web Application |
Front-end to Mica Server providing client interface to manage Mica Domain content as well as to administrate and configure access permissions and secure connections. |
Mica Python Client |
Python front-end to Mica server providing services for administrative command-line and automation tasks. |
Mica R Client |
R front-end to Mica server providing services for Mica content analysis and reporting. |
The diagram below illustrates the relationships between the Mica server and the other tiers:
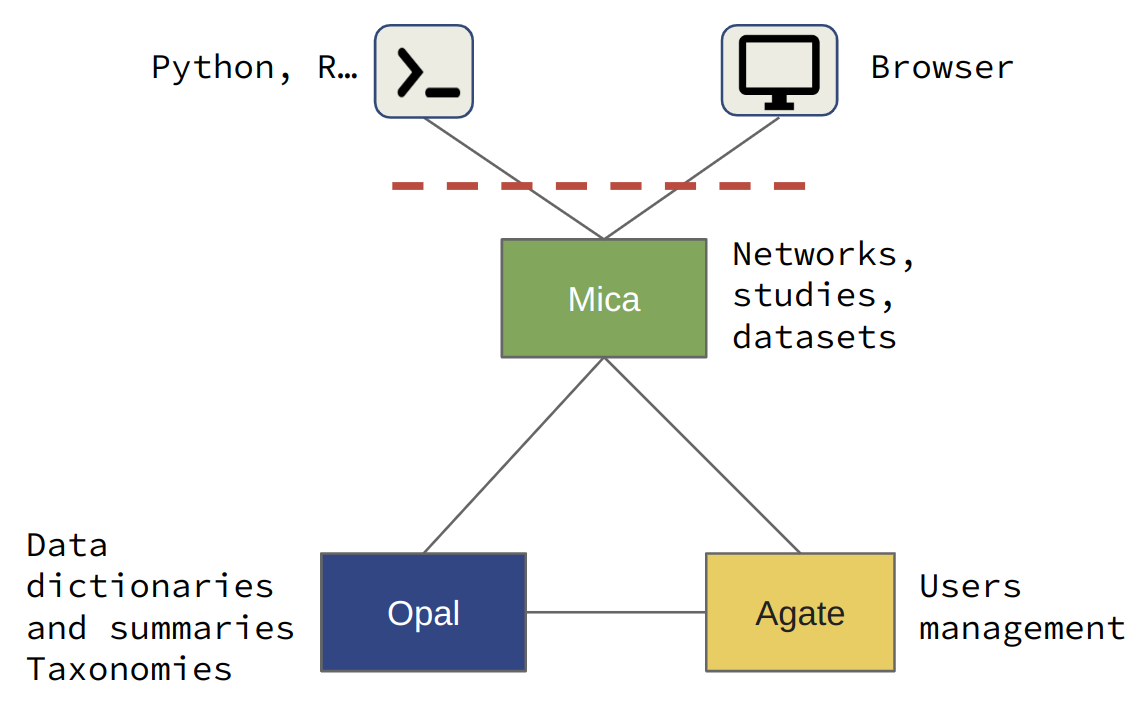
Mica system regular architecture
The system architecture can be simplified by replacing Opal with data dictionary and taxonomy files (or remote services using Plugins):
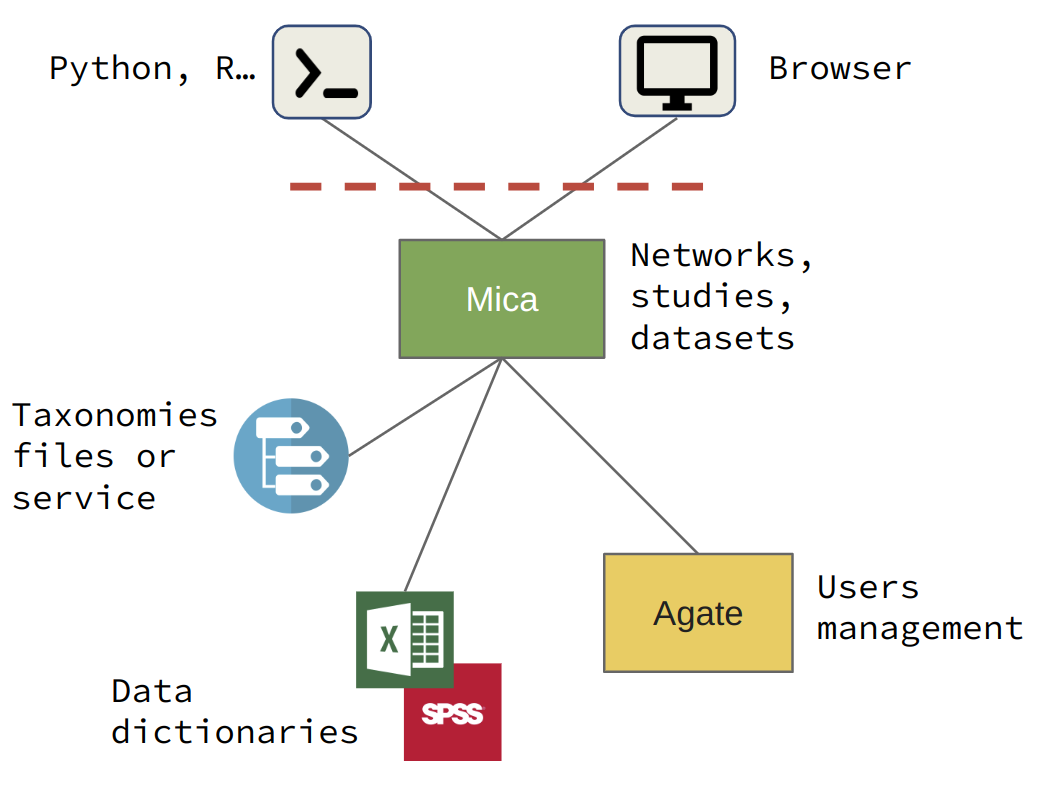
Mica system light architecture
Note that it is possible to combine Opal with data dictionary and taxonomy files.
Mica Server
Editors and reviewers of the Mica web portal content can access to the web interface of this server as described in the Mica Web Application User Guide. Data access request form can also be configured through this web interface.
Mica server is a client of Opal and Agate servers.
Opal Server
Note
Since Mica 5.2 it is not required to manage data dictionaries and taxonomies in a Opal server. The data dictionaries can be provided by Excel files attached to the datasets. The taxonomies can be defined by local configuration files or can be downloaded from a remote service (using an appropriate plugin).
Opal application is used for:
defining data dictionaries (variables),
storing data,
providing data summary statistics.
Opal offers well established security controls, allowing to NOT expose individual-level data. Note also that the Opal server is only accessed by the Mica server, reducing the risk of data compromisation from a malicious end user.
Installation and configuration guides can be found in the Opal documentation.
Mica expects at least one Opal server when some datasets are defined. Additional Opal servers can also be identified to access to distributed datasets.
Agate Server
Agate application is used for:
having a user directory shared between OBiBa’s applications,
having centralized services such as profile management and email notifications.
Installation and configuration guides can be found in the Agate documentation.